Federated learning for medical datasets
Written By: JuWon Park
“Garbage in, garbage out”, or GIGO, is a common saying in computing that describes the importance of human decision-making to create quality datasets for accurate models. In previous articles, we mentioned the potential applications of AI-driven diagnostics in institutions like hospitals. The limitations in creating large, unbiased datasets are clear, but a novel machine learning method aims to address these. Federated learning is a collaborative learning approach that can be used to gather privatized and quality information for a specific population using the algorithm.
One limitation of deep learning diagnostic models is subtle institutional data biases that affect the performance of models when used on institutions (such as varying departments within the same institution or hospitals), not in the dataset. Medical institutional biases arise from differences in demographics, instrument/equipment, etc. In order to eliminate biases, a collaboration between institutions to aggregate more diverse data has been proposed (Sheller et al., 2020).
In collaborative data sharing (CDS), multiple institutions send patient data to a single location for model training. Still, this approach is limited by privacy, technical, and data ownership issues when scaled to larger groups of institutions. Federated learning (FL) addresses these through a data-private collaborative learning method. This means that instead of sending patient data to a centralized location, individual collaborators train the model using their own data, parallel training, and send the model updates to the central server. This central server is called the aggregation server, as the name suggests. Still, the merits of using larger datasets from these data-private collaborative learning require clarification amidst the restrictions that CDS can pose such as consistency (Sheller et al., 2020).
Other CDS approaches include institutional incremental learning (IIL) and cyclic institutional incremental learning (CIIL). Instead of sending data to a central repository, the model is trained by each institution and passed along, serially training the model. However, these methods can lead to biases where the model favors the most recent data, in what is called “catastrophic forgetting” (Chang et al., 2018).
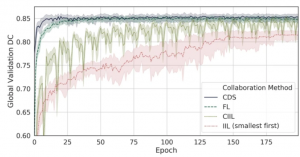
Caption (taken from article): “Learning curves of collaborative learning methods on Original Institution data. Mean global validation Dice every epoch by collaborative learning method on the Original Institution group over multiple runs of collaborative cross-validation. Confidence intervals are min, max. An epoch for DCS is defined as a single training pass over all of the centralized data. An epoch for FL is defined as a parallel training pass of every institution over their training data, and an epoch during CIIL and IIL is defined as a single institution training pass over its data.” (Sheller et al., 2020)
This study was able to show that, on average, the model performance of CDS models was 3.17% and FL models were 2.63% greater than the single institution models, showing that larger access to data benefits model quality. Overall, FL showed, on average, the best rate of model improvement over epoch which contributes to more stability, winning over incremental methods such as CIIL, IIL, and CDS. More specifically, the study validates the benefit of using ten institutions to increase the diversity and size of data (Sheller et al., 2020).
This study and others show the potential of FL in creating multi-institutional machine learning collaborations that can meet data protection requirements, which will resolve privacy concerns. However, security issues such as attackers or malicious participants tampering with the training data or extracting information about the training data is still a concern. Using prevention measures on threats is key to safely implementing FL to create powerful diagnostic models with fewer institution biases. Real-world multi-institutional datasets will become critical in building bigger and better datasets for higher quality diagnostic models that will advance future medicine.
Works Cited
Chang, K., Balachandar, N., Lam, C., Yi, D., Brown, J., Beers, A., . . . Kalpathy-Cramer, J. (2018). Distributed deep learning networks among institutions for medical imaging. Journal of the American Medical Informatics Association, 25(8), 945-954. doi:10.1093/jamia/ocy017
Sheller, M. J., Edwards, B., Reina, G. A., Martin, J., Pati, S., Kotrotsou, A., . . . Bakas, S. (2020). Federated learning in medicine: Facilitating multi-institutional collaborations without sharing patient data. Scientific Reports, 10(1). doi:10.1038/s41598-020-69250-1